|
|
|
Dynamic QoS for Videoconferences
|
|
Collective work by Angelos Varvitsiotis, Dimitrios Kalogeras, Dimitris Primpas, Dimitris Daskopoulos,
Savvas Anastasiadis, Apostolis Gkamas, Faidon Liabotis, Spiros Papageorgiou and Andreas Polyrakis
|
|
| Problem definition |
Figure 1 shows a typical setup for a videoconference between three users of GRNET. As shown in the figure, when users UA, UB and UC are having a videoconference using GRNET's central MCU facility, they all exchange traffic with the MCU (traffic from each of UA, UB and UC is drawn with the respective color in the figure). In the event of congestion, the quality of the whole videoconference can be affected. Even if congestion occurs on a single network link, when video and voice traffic from one user to all others traverses that link, all receiving users experience bad quality. |
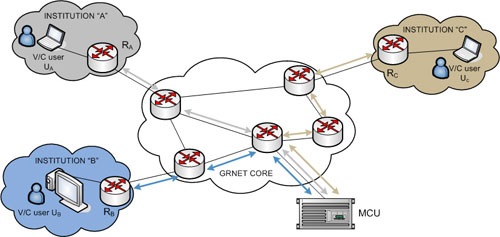 |
| Figure 1 [Enlarge] |
It is worth noting that, despites ample bandwidth provisioning, congestion occasionally does occur. Currently, links between institutions (as "A", "B" and "C" in the figure) and GRNET have 1 Gbps of bandwidth, however there are institutions that use 80%-90% of that bandwidth, with threatening spikes approaching the top 100% line quite often. Thus, congestion is not a fictitious problem. It does occur, and QoS techniques are needed to ensure good VC quality. |
|
| Why the naive approach is not the best thing to do |
So, why don't we just "solve" the problem by applying the following two simple rules: (1) treat traffic from the MCU to every destination as priority traffic; and (2) treat traffic from every source to the MCU as priority traffic. However, this would open a number of issues, among which a severe security hole.
The first issue is admission control: a static rule like (2) above must be imposed at the network perimeter (say, at the connection of Institution "A" to GRNET) to make sure traffic is marked as priority throughout its whole journey trhough the network. However, how much traffic would we allow through? One VC user's worth of traffic (say, 1Mbps), is enough? No, because then another user connecting from the same Institution "A" to the VC would add traffic summing up beyond that limit, resulting in poor quality for both users. How about two users' worth of traffic, say, 2Mbps? Then the same problem would occur with a third user. So, the only bullet-proof solution with the naive approach would be to allow all possible traffic up to a maximum (say, 10Mbps) for each institution. This method actually bypasses the problem of admission control, by admitting virtually everyone in.
This brings in the second issue of the naive approach: without admission control, if a malevolent user from Institution "A" wishes (or worse, a set of malevolent users from various institutions wish) to cause trouble, the(se) user(s) can very easily orchestrate a denial-of-service attack, by injecting illegitimate traffic to the MCU (illegitimate RTP packets cannot easily told apart and filtered out by ordinary router mechanisms such as access-lists). This illegitimate traffic would be treated with priority throughout the network, with the danger of summing up to high bandwidths and disrupting the normal operation of the network, the MCU or both. |
|
|
| So, what does "Dynamic QoS for Videoconferences" do? |
In essence, our method creates, propagates, and installs on-the-fly rules for admission control and marking of VC traffic at the network perimeter (where traffic is marked and policed for conformance to contracted-to traffic profiles). In this manner, only traffic from legitimate VC users is prioritized. No other users may inject priority traffic in the network. Moreover, our method performs admission control, so that if multiple users from a given institution participate in a VC, it is possible that only some of them will be allowed to inject priority traffic, while others will not.
|
| How does it work? |
In order to enjoy this service, the participating institutions have to reserve in advance a maximum amount of "VC bandwidth". This will be used for admission control, as explained further below. Assuming that all institutions have made such reservations, the mechanisms of our service are shown in Figure 2 below. As shown in the figure, the dynamic VC QoS service is based on a RDBMS/Routing server, positioned in the core of the network. This server runs periodically scripts that collect the required information and a routing server that passes information back to the network as /32 addresses. The network is pre-configured to use these routes as router Forwarding Information Base (FIB) entries, with packets that match these entries being mapped to the Expedited Forwarding forwarding class and thus given absolute priority. |
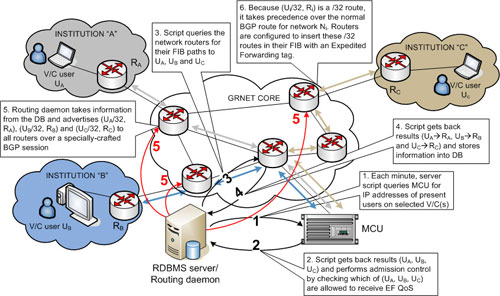 |
| Figure 2 [Enlarge] |
|
Admission control: the server periodically (once every 60 seconds) executes a script that queries the MCU and collects data about connected users (see step "1" on the figure). Besides the connected users, the script obtains information about the specific videoconference, the traffic profile of each connected user, etc. After getting these data, the script in step "2" decides which of these users deserve to receive priority service, based on the VC in which the user participates (not all VCs may receive priority traffic), the pre-allocations made by each institution in terms of bandwidth, the amount of bandwidth required by each new user, and on the amount of bandwidth currently being "consumed" by other, preexisting users from the same institution. This method of admission control guarantees two types of checks: a "coarse-level" admission control check, which ensures that no user can receive priority service unless the user is accepted in a VC, thus mmitigating drastically the potential of a denial-of-service attack, and a "fine-level" check, which ensures that no user can receive priority bandwidth beyond the allocation of their own institution, thus ensuring that all existing users already admitted in the system will continue receiving priority service without being affected by new users trying to enter.
Routing daemon process: once the script has decided which /32 addresses deserve priority traffic, it inserts these addresses into a database, which serves as a coupler between the script and the routing daemon process. The routing daemon then announces these addresses to the network as explained in this and the next paragraphs. The script is allowed to enter new addresses into the DB and to remove addresses of users who have withdrawn from a VC, but it cannot modify flags of existing addresses in any way. The routing daemon is responsible for checking for "new" addresses and then flagging them as "old" - where "old" addresses are the ones that have already been announced to the network. With this method, the routing daemon keeps a "routing table version", which is only changed when a new address appears or an existing one is withdrawn.
Source route determination: the routing daemon would be now ready to announce user addresses to the network, except for one minor detail: in order for these /32 routes to be installed into the FIB of network routers, a "next-hop" is needed. In case of a normal routing protocol, the advertising router sets itself as the "next hop", and each router that receives this route advertisement uses its own routing table to determine that interface among all of its interfaces into which this "next hop" corresponds. However, this is not possible here: if routes are announced in this way, traffic towards all VC users will flow back to the RDBMS/Routing server. Instead, the (BGP) routing protocol has to be "hacked" and the true "next hop" address for each of UA, UB and UC must be set to the real address of the respective advertising router (RA, RB and RC, respectively). How can the routing process get by this information? Our choice was to query the network (by means of a "pathfinder"-like web service, actually the same one used for GN2 SA3 operations).
Pathfinder service: the pathfinder service accepts as input a route and replies back the address of the (first non-GRNET, that is the "client") neighbor router that advertises this route into GRNET. Given the fact that GRNET is an MPLS network, we have implemented this service by means of only two route queries. Each query asks the question "where from do you know this route?" to a network router. The first such query is addressed to a certain core router, which maintains MPLS LSPs to all other GRNET routers. So, the reply from that router always points to the correct border GRNET router. The second query is addressed to that border router, and returns the neighbor router address. This is the "next hop" address to be announced to the network from the routing daemon, as explained in the previous paragraph. This web service is implemented via SOAPLight using a 50-line perl script, which asks the network routers over telnet. Since the routing server knows all internal GRNET routers, it would be easy to re-write this service so as to pick the narrowest matching route from the daemon's routing table and then perform the router FIB queries (a FIB query is needed to return LSPs) over SNMP, thus avoiding using the expensive (and, for some, dangerous) telnet step.
Network router setup: once the next-hop address Ri is found for each user address Ui, the routing server announces to all network routers a set of /32 route/next-hop pairs as {(Ui/32, Ri)}. Before that announcement, network routers know routes of the form {(Ni/Mi, Ri)}, where Mi<32 is a network mask specifying the width of the network Ni to which Ui belongs. GRNET's routing policy does not allow Mi to be more that 24. Thus, it is guaranteed that the route {(Ui/32, Ri)} is narrower than {(Ni/Mi, Ri)} and therefore will take precedence. The BGP router configuratin is crafted to "tag" all routes learned from the VC routing daemon with a special internal tag (Cisco-specific), termed a "qos-group". This is like a DSCP mark, only it is internal to the router and accompanies a packet only while this packet lives in the router's memory. Using this "qos-group" tag as a matching criterion, matching packets (i.e., packets to/from Ui and from/to the MCU) are classified as priority traffic and sent to a low-latency queue. Coupled with BGP-inserted FIB entries tagged with qos-marks, Cisco calls this technique QoS Propagated Policy via BGP, or QPPB for short (Junipers are known to have equivalent functionality). |
|
| How can this be any good in a multi-NREN environment? |
This is discussed in a paper of ours, submitted for publication. Details will follow. |
|
|
| Can I have the code/configuration examples? |
Sure; only, please take into account that many things are vendor-specific. This does not mean that the methodology is vendor-specific. The whole system is modular, so modules can be exchanged and new modules can be written for machinery from other vendors.
The script that queries the MCU is Polycom-specific. It can be downloaded from here.
The database into which routes are inserted is a simple MySQL database. The required schema can be found here.
The routing daemon is based on Quagga version 0.99.3, to which a set of patches are applied. The patches can be found here.
The pathfinder service is implemented by a perl SOAPLite-based script that can be found here.
The routing configuration is Cisco-specific. Routing configuration excerpts can be found here.. Junipers are known to have equivalent functionality - apologies, we cannot provide Juniper examples for the time, since we do not have access to a Juniper-based network. If anyone wishes to contribute such examples, we will be happy to host them. |
|
| Credits |
The overall design and implementation is the result of collaborative work from the GRNET Virtual NOC (VNOC). For details, see http://vnoc.grnet.gr.
The MCU query script has been written by Dimitris Daskopoulos and Savvas Anastasiadis,
from VNOC's Conferencing team (mail rts at grnet dot gr).
The database schema and the "sql" Quagga routing daemon have been written by Faidon Liabotis (mail faidon at admin dot grnet dot gr).
The "next-hop" hack to Quagga via a WS-based lookup has been written by Dimitris Primpas and Apostolis Gkamas ((mail primpas at cti dot gr , gkamas at cti dot gr).
The QPPB-based router configuration is the result of an idea and many painful hours of trials by Dimitrios Kalogeras and Angelos Varvitsiotis (mail dkalo at noc dot ntua dot gr , avarvit at admin dot grnet dot gr).
The final QoS router setup was made and tested collectively by Dimitrios Kalogeras, Dimitris Primpas, Apostolis Gkamas, Spiros Papageorgiou and Andreas Polyrakis (mail dkalo at noc dot ntua dot gr , primpas at cti dot gr , gkamas at cti dot gr , papapge at noc dot ntua dot gr, apolyr at noc dot ntua dot gr).
The technical coordination has been the responsibility of Angelos Varvitsiotis (mail avarvit at admin dot grnet dot gr).
This work was supported by GRNET's Virtual NOC project, funded by the Greek Programme for Information Society ( http://www.infosoc.gr). |
|
|
|
|
|
|

